指针和数组
一重声明
以下这些问题,我相信即使是最基本的初学者也不会有太大困难:
你会声明数组吗?
int a[5]; // 包含 5 个元素。
你会声明指针吗?
int *a;
二重声明
你会声明双重指针吗?
int **a;
你会声明二维数组吗?
// 第一维长 5,第二维长 7 int a[5][7];
那你会声明指针的数组吗?
// 数组的长度为 7 int *a[7];
你会声明(指向)数组的指针吗?
int (*a)[5];
思考题 1:二维数组、数组的指针、指针的数组,这些东西是一样的吗?有相同的吗?还是各不相同?
答案:可参考《说出来你们可能不信,但是数组名确实不是指针常量》。以后我也可能会写。
一定要注意,用指针类型代替数组是错误的做法——对于多重数组和多重指针,它们下标的语义是不一样的。无论几维数组,它们的内存布局总是线性的,指针却不然,有多少重就会真的做多少次跳转。
三重声明
你会声明【数组的指针】的数组吗?
int (*a[9])[5];
你会声明指向【指针的数组】的指针吗?
int *(*a)[5];
让我们来试着验证一下。怎么验证呢?只要按照概念(比如数组的指针的数组),一步一步构造并且赋值,最后能编译通过,没有警告,就说明我们从概念到代码的翻译是对的。
int a1 = 1;
int a2 = 2;
int a3 = 3;
int a4 = 4;
int a5 = 5;
int aa1[5] = {1, 2, 3, 4, 5};
int aa2[5] = {1, 2, 3, 4, 5};
int aa3[5] = {1, 2, 3, 4, 5};
// 二维
int *aa[5] = {&a1, &a2, &a3, &a4, &a5};
int (*aa1d)[5] = &aa1;
// 三维
int *(*a)[5] = &aa;
int (*b[3])[5] = {&aa1, &aa2, &aa3};看明白了吗?这背后的原理是什么呢?
实际上这体现了某种递归性——
如果一个声明形如
T *D(假设变量ident在D中),而T D声明了一个【定语 +T】类型的变量的话,那么T *D就声明了指向类型 T 的【定语 + 指针】ident。
如果一个声明形如 T D[n](假设变量 ident 在 D 中),而 T D 声明了一个【定语 + T】类型的变量的话,那么 T D[n] 就声明了长度为 n 的、类型为 T 的【定语 + 数组】ident。
有些晦涩,是不是?让我们再拿例子回顾一下。比如 int (*b[3])[5] 中:
- D 就是 (*b[3]),T D 则是 int (*b[3]),说明 a 是一个长度为 5 的,如果说 int (*b[3]) 声明了一个【什么】of int 的话,int (*b[3])[5] 就声明了一个【什么】的、长度为 5 数组 of int
- 再拆解得 int b[3],是一个【长度为 3 数组 of】 int(注意 T 是 int),说明 int (*b[3]) 声明的是【长度为 3 数组 of】【指向 int 的指针】,从而上文的【什么】,就是【长度为 3 数组 of 指向 <它> 的指针】,这个 <它> 就是这个定语修饰的对象要填入的地方。
- 让我们把第一步的【长度为 5 数组 of int】填进这个 <它>,就会得到【长度为 3 数组 of 指向 【长度为 5 数组 of int】 的指针】。
- 用人话说,就是一个长度为 3 的数组,它包含的是一些指针,这些指针指向长度为 5 的 int 数组。这和我们的代码 int (*b[3])[5] = {&aa1, &aa2, &aa3} 也是一致的。
以上便是标准中对类型的「递归」定义。这看起来对人类太不友好了,但是我们也更人性化的等价解读——「替换」。比如还是对这个 int (*b[3])[5]:
- 注意 [3] 的优先级比 * 要高。我们先把 b[3] 替换成 c,那么 b 的类型就会是含有 3 个元素的、c 的类型的数组。
- int (*c)[5],由于括号的存在,我们这时候会替换 *c,而不是 c[5]。假设替换为 d,从而 int d[5],那么 c 是一个指向 d 的类型(的变量)的指针。
- d 类型就很简单了,是一个 5 个元素的 int 数组。
- 那么我们将以上串联起来—— b 是【含有 3 个元素的】【元素是[指向〔有 5 个元素的 int 数组〕的指针]】的数组。看,还是一样的吧。
实际上这就是自底向上而不是自顶向下解读那样的递归解析规则罢了。
而如果我们不慎多加了一个括号,比如 int (*a[9])[5] 变成了 int ((*a)[9])[5],那么结果就会变味了。拆解到 int ((*a)[9]) 的时候,会优先拆解成数组,从而最后变成了指向数组的数组(二维数组)的指针了。
比如 int *(*a)[5]——
- 我们可以把 (*a) 替换成 b,这样 a 便是指向 b 被定义的类型的指针。
- 而 int *b[5],我们又可以把 b[5] 替换成 c(可以看出,这样的理解下,「下标」要比「解引用」,就是小星星,优先级更高),那么 b 便是容纳 c 的类型的、长度为 5 的数组。
- 最后 int *c,则 c 是指向整数的指针。
- 从而原本声明的 a 是一个指向长度为 5 的、元素是整数指针的数组的指针,也就是指针的数组的指针。
思考题 2:为什么 int *a[7] 和 int (*a)[5] 一个是指针的数组,一个是数组的指针?括号是怎么起作用的?
这样的思想,同样可以套用到函数类型上(因为函数类型也是这样递归定义的)。
函数
你会声明一个函数吗?想必大家都会。
int func(int, int);
这就声明了一个名为 func,接收两个 int 型参数的变量,可以这么用:
int result = func(1, 2);
那么你会声明一个函数类型的变量吗?
嗯哼?
等一下?变量?其实你在你声明函数的时候,就已经等于在声明了一个函数类型的变量了。只不过函数「变量」不支持用等号「赋值」。要修改它的「值」,必须通过花括号语法,撰写「函数体」,比如:
int func(int a, int b) {
return a + b;
}这是大家熟知的内容。这样,我们连函数类型「变量」的声明也知晓了——它就是我们熟习的函数声明。可是既然它不可以赋值,也只能定义至多一次,它就不是个「变」量了,那么会写它的类型又有什么用呢?
其实,我们还可以拿来传参呀!比如上面的 func,就是把两个参数加起来。现在我们想利用这个函数,构造一个把单个整数加 1 的函数。我们该怎么接收这个函数作为变量的?这时候我们就需要它的类型了:
int apply_on_1(int func(int, int), int);
int apply_on_1(int func(int, int), int b) {
return func(1, b);
}原来函数类型也可以这么用啊!
复杂函数
现在问题又来了,你会声明返回以上各种类型的函数吗?你会把这些类型(包括函数)随意组合起来吗?比如一个接收「(数组的指针)的数组」,返回「数组的指针」的函数。一个最简单的实现就是返回这个「(数组的指针)的数组」的第一个元素,它必然是一个「数组的指针」。
内容知道了,可是类型又该如何写呢?参数类型是好写的,我们只要把「(数组的指针)的数组」类型依样照搬到参数列表里就行:
some_type return_first(int (*a[9])[5]);
问题就化归到了 some_type 怎么写上。实际上,我们还是只要牢记「递归」或者说「替换」原则。我们把
return_first(int (*a[9])[5])
这个整体当作一个变量,它如果是一个「数组的指针」。它会处在什么位置呢?回顾「数组的指针」的声明:
int (*a)[5];
这时候我们只要把 return_first(int (*a[9])[5]) 作为一个整体,替换到上面的 a 中去,就成功了:
int (*return_first(int (*a[9])[5]))[5];
很简单舒畅是不是?
其实作为在函数声明中,参数名是可以省略的,即使它是被「包裹」在中间的。这就是说,以上定义等价于
int (*return_first(int(*[9])[5]))[5];
而如果我们有一个接收以上类型,返回 double 的函数,我们就可以把 return_first 也省掉,比如
double complex_func(int(*(int(*[9])[5]))[5]);
这样太吓人了。
函数指针
有人会问,为什么只谈函数指针,不谈函数数组呢?C 语言不允许声明函数数组。想想前文,函数不能赋值,只能定义,如果声明了函数数组,我们根本就无法操作啊。但是函数是可以取地址的,所以我们可以定义并广泛使用函数指针。
函数指针,其实很简单。你已经知道声明 int 类型的指针是:
int *p_int;
那么声明 int func(int, int) 类型的指针 p_func,就应该是把 *p_func 当作是 func 一样带入进 int func(int, int),也就是:
int (*p_func)(int, int);
为什么要加括号?这是因为函数参数列表的优先级相较指针声明的优先级为高,如果不加括号,p_func 就首先会被认为是一个函数。我们前面已经探讨过这个问题了。为什么是把指针带入进函数声明,不是反过来,把函数带入进指针声明,也就是假装 func(int, int) 是一个 int *?那就是声明一个返回整数指针的函数了,而不是一个函数的指针。
函数和函数指针
函数和函数指针有什么区别?最显著的区别就是函数指针也是指针,可以赋值。比如:
int func2(int a, int b) {
return a * b;
}
int (*p_func)(int, int) = &func2;
int (*another_p_func)(int, int) = func2;有人会问,第二个是什么?为什么不用「取地址」就可以把一个「函数」赋给「函数指针」?这正是「函数」的种种特殊性之一——对于所有除了「取地址」(&) 和「取大小」(sizeof) 之外的操作(实际上并不允许 sizeof 作用于函数),函数总是会隐式地转换为指向它的指针。所以当你把函数赋给一个变量,实际上把它的地址赋给那个变量,当你把函数的地址赋给一个变量,你还是在把它的地址赋给那个变量。
从此,我们就知晓了「数组」、「指针」和「变量」任意混合的类型声明。
修饰符
所谓修饰符,就是 cv-qualifiers,也就是 const 和 volatile。volitile 是一个如果不面向硬件编程就不太接触到的东西,它表示变量可能被程序之外的东西修改(你可以不用管它)。const 则是较常见的修饰符。它表示所指向的对象是不可修改的。比如:
int const a = 0; a = 1; // 会报错,因为 a 是 `const` 的。 const int b = 0; b = 1; // 同样会报错,因为 b 是 `const` 的。
我们可以看到,const 可以放在类型前后,如 int const 和 const int,效果一样。
同样的:
int * const a;
和
const int * b; int const * c;
全然不同。
让我们套用「替换」的观点——int const * c 表示 *c 是一个 int const(相应地,对于 b 是 const int,也就是 int const),就是说,c 是一个指向整数常量的指针,但是 c 本身不是一个常量,是可以随便改的。
int v = 5; int const * c = &v; // NULL 表示 0。不会报错,因为 c 可变。 *c = 7; // 会报错,因为 `*c` 不可变。
而 int * const a,则是被 const 修饰的 int *,也就是不可变的整数指针,a 本身是常量,不能改,指向的地方倒是可以改。
那么 const 如何描述一个「不可变」数组?const 该放到数组声明哪里呢?好像没有地方可以放哦。
什么?常量数组?不存在这种东西。我们知道数组是不可赋值的,只能至多定义一次,它本身就是不可变的,所以没有 const 也很科学。
「不可变」函数也是不存在的,理由同上。当然函数的返回类型和参数类型都可以是 const 的,很容易举一反三。
typedef
typedef 很有用,它可能是我们“可读”地声明这些复杂类型的方案。那么如何 typedef 这些复杂类型的?
你可能见过
typedef int a;
它把 a 声明作 int 类型的别名。 你也可能见过
typedef long long LL;
它把 LL 声明作 long long 类型(注意 long long 是一个类型)的别名。
这些都是简单类型,那么复杂类型呢?其实和上面一模一样就可以了。你可以把任何一个变量声明语句之前加上 typedef,从而获得一个类型别名声明。本来要声明的「变量」名,就是现在声明的「类型别名」。比如:
typedef int (*a[9])[5];
就是把 a 声明作数组的指针的数组。以后可以像
a v_a;
这样声明一个名为 v_a 的「数组的指针的数组」。为了增加可读性,你可以多使用渐进的 typedef,每次只多定义一层——比如第一次定义一个数组类型,第二次定义指向第一次那类型的指针,第三次定义第二次那类型的数组:
typedef int int_array[5]; typedef int_array * ptr_to_int_array; typedef ptr_to_int_array array_of_ptr_to_int_[7];
(说实话,工程上这样有多大意义,甚至是否需要这样的复杂类型,都是有争议的。不同的人有不同的看法。比如 Linux 内核那一卦的人就不主张对 struct 进行 typedef,而 libuv 里这样的 typedef 又满天飞。又比如很多人不主张对指针类型进行 typedef。工程习惯上的争论,是永不过时的议题。)
网易笔试题
前一阵子,某网易校招笔试题引起了轩然大波,受到广泛吐槽。对题目的价值取向我们暂且不表,不妨用刚刚讨论过的内容来试着分析一下。它是 C++,不过不超出 C 的范畴(C++ 引入了类和模板,相关情形对类型的解析会复杂得多)。题目是分析这几个类型的意义:
int *ptr[n]; int (*)ptr[n]; int *ptr(); int (*)ptr(); int(*((*ptr(int, int))))(int);
我们先概览一下,其中有两个显著的错误——(*)是非法的,把一个这样的碎片单独括起来是没有意义的。(引用标准)实际上标准中也不允许出现这样的情况,所以编译器当然也会报错了。我们不妨猜测一下,原本的面貌是 (*ptr) 而不是 *(ptr),这就很有意义了,2、5 改过之后看起来也不跟别的选项重复,很合理。
我们来看改过后的样貌:
int *ptr[n]; int (*ptr)[n]; int *ptr(); int (*ptr)(); int(*((*ptr(int, int))))(int);
这么看来,第 1、2 项我们在最开始就讨论完了。第 3、4 项也都是最基本的情形。看看第五项,我们应该从内而外地看,ptr 是一个函数(我们前面说过,参数列表比星号更高级,这里不是(*ptr)(int, int),而是*ptr(int, int)。
它接收两个都为 int 类型的参数。那么它的返回类型是什么呢?记住我们当时是怎么声明函数类型的?把 ptr(int, int) 看作一个整体,它被声明的类型,就是它的返回类型。我们用 c 代表它的话:
int(*((*c)))(int);
可以看到,有两对多余的括号,我们来删减它:
int(**c)(int);
c 是一个指向【函数指针】的指针(二重指针),这次我们不想一步一步写了,就脑补吧。这个【函数指针】指向的函数接收一个 int 类型的参数,返回一个 int 类型的结果。
综上所述,ptr 是一个函数,这个函数接收两个类型为 int 的参数,返回一个指向【函数指针】的指针,第二个函数接收一个类型为 int的参数,返回一个 int 类型的结果。
这对吗?我们不妨用代码来确证,如果按照这样的思路写出的代码能编译,我们就对了:
int unary(int a) {
return a + 1;
}
int (*p_unary)(int a) = unary;
int(*((*ptr(int a, int b))))(int) {
return &p_unary;
}编译通过,大功告成!
牢骚
C 语言的类型声明,带来了许多像这样的麻烦。诸如 Scala 和 TypeScript 之类的一部分现代语言,选择了后置类型声明,比如 a : int = 3(示意,不是这两种语言的代码)代替了 int a = 3,而 char func(int a, double b) 则被 func (a: int, b: double) -> char 代替。一个返回函数的函数,可能可以写作 d_func(a: int) -> (func(b: int) -> int)。当然 C 语言里不可以这么做,函数是不可以返回的。只能返回函数指针,比如 int (*(d_func(int a)))(int b)
其实后置的好处倒没有那么主要,虽然向右的箭头更符合大多数人的阅读习惯,毕竟前置可以看成是后置的完全对偶。C 语言的麻烦在于两个:
一个是,虽然左右可以完全对偶,但是 C 语言的参数列表在右边,类型却在左边,参数的类型,它们被函数名分开了,无法建立箭头那么直观的认识。如果参数列表前置倒也好:int <- (int b) (*( <- (int a) d_func))。虽然从右向左有些不习惯,但是是不是好像有些感觉了?
另一个是,数组的声明,元素类型在左边,长度却在右边。这其实跟第一个麻烦是一回事,所以很多语言引入了形如 int[5] a 的语法,[5] 直接修饰 int,看起来就要直观得多,比如 int (*a[9])[5] 就变成了 ((int[5])*)[9] a,这样看起来毫不费力,非常直观,不需要任何学习。
当然很多其他语言都没有指针,这也会让类型声明看起来更简洁。不过这不是主要的,因为 C 语言的指针声明,基本还是合理的。当然 TypeScript 还是略有繁琐,它的类型声明必须要指出参数名,比如:
function map<A, B>(func: (a: A) => B, elem: A): B;
这无疑是增加了阅读难度,虽然比起 C 已经很低了,但是面对高阶函数类型,还是显得力不从心(C 语言根本没这个需求,因为它不支持就地地、嵌套地创建函数,虽然可以有高阶函数签名,但是根本没有实用价值。虽然有一些 GNU 扩展,但是手动管理内存也会让高阶函数苦不堪言)。
Scala 虽然支持不需要对高阶函数标注参数名,但函数本身的参数列表和类型签名还是耦合的。而诸如 OCaml 之类的 ML 系语言,以及深受其影响的 Haskell(家族,包括 Idris, Agda 等),采取了更激进的、函数类型签名和函数实体完全分开的策略,可以轻松声明复杂类型,比如最常用的函数 foldr 长这样:
foldr :: Foldable t => (a -> b -> b) -> b -> t a -> b
类型之间的关系显得十分清晰明了。这将我们带入了一个玩弄类型的世界。不过这都是后话了。
从这点上来看,由于声明时可以完全省略参数名, C 语言反而显得比 Scala 和 TypeScript 先进。可是在后续实现这个函数的时候,还是要照抄类型,而不能根据参数位置自动推导出(不写会被默认为 int),不免显得有些遗憾——然而这之中也有必然。个中详情,足够畅谈数日,这里无暇叙述。
练习
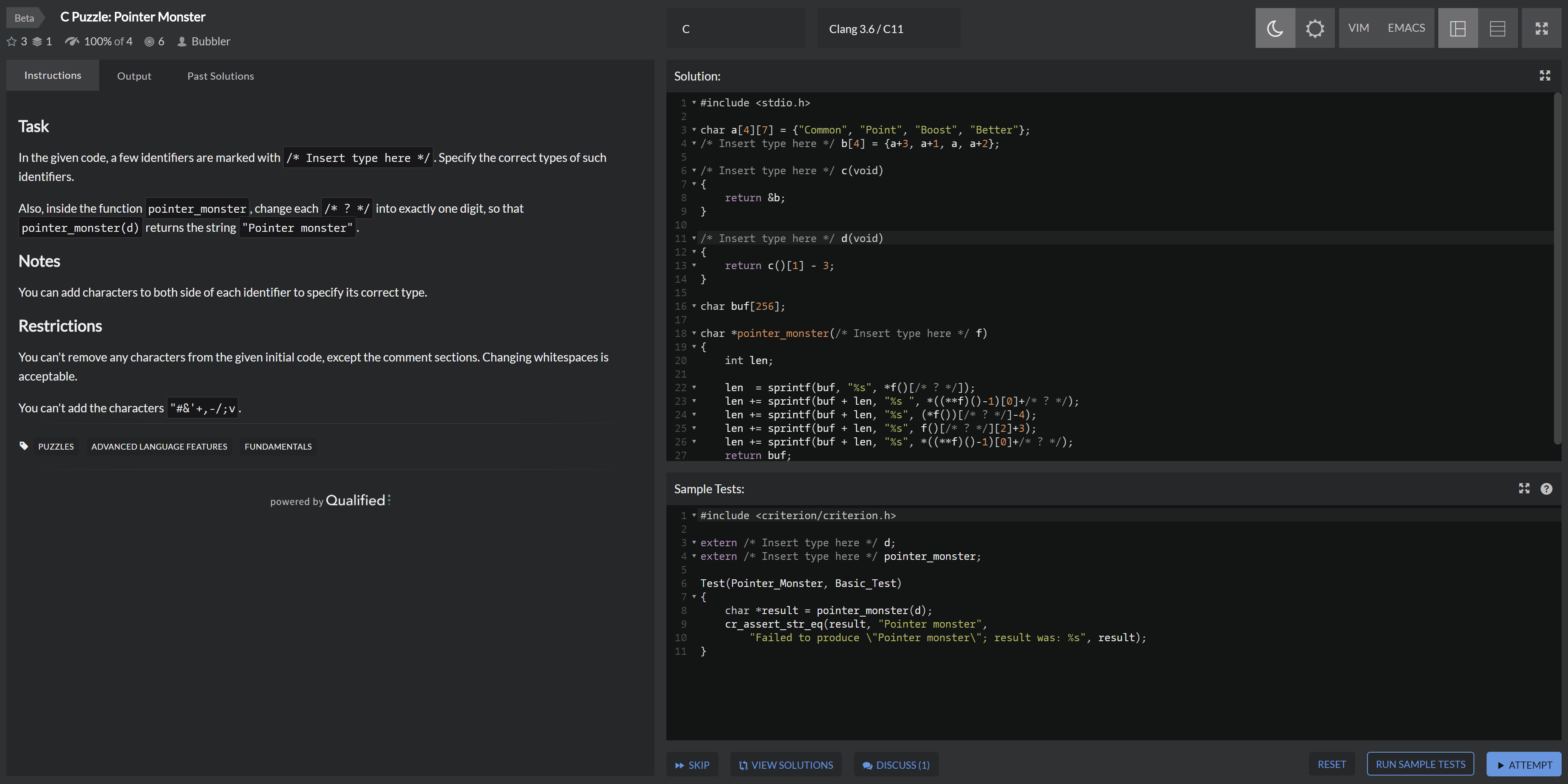
在 C Puzzle: Pointer Monster 定义各种复杂类型,进行下标运算,并通过测试。
广告时间
 Codewars.com 是一个很好的综合性、游戏化 OJ,除了算法(多是入门级的)之外,考察语言特性(较为深入)是其一大亮点,同时有很多 Haskell 方面的内容,包括我们喜闻乐见的读论文然后完形填空。题图是 Codewars 上上述练习的界面截图。
Codewars.com 是一个很好的综合性、游戏化 OJ,除了算法(多是入门级的)之外,考察语言特性(较为深入)是其一大亮点,同时有很多 Haskell 方面的内容,包括我们喜闻乐见的读论文然后完形填空。题图是 Codewars 上上述练习的界面截图。
后记
以上内容,都是基于 C 语言标准演绎而成(C11 draft N1548,免费,正式版是付费的)。作为一篇入门级的小品文,为了阅读效果,我选择不详述过程和原文。水平有限,错误之处在所难免,欢迎读者指正。
")

你的英文版是假的
good explanation